

NVIDIA 4QFY26 Earnings: The Tokenization of Software
NVIDIA’s Q4 wasn’t about beating estimates, it was about proving that software has shifted from pre-recorded to generative, and that compute is now a revenue engine.

TL;DR
Software is moving from pre-written code to real-time generation: a structural compute multiplier.
Agentic AI proves tokens are monetized now, not hypothetical future demand.
NVIDIA isn’t selling chips; it’s selling rack-scale AI infrastructure that locks in the generative economy.

From Bloomberg:
Nvidia Corp. failed to impress investors with its latest forecast, signaling that concerns about an overheated AI economy will continue to dog the company. Fiscal first-quarter sales will be about $78 billion... Though the average Wall Street estimate was $72.8 billion, some analysts had projected numbers approaching $80 billion.
The market looked at a company growing revenue 73% year-over-year at a $68 billion quarterly base, beating every published estimate, guiding $5.2 billion above consensus, printing 75% gross margins, and shrugged. Bloomberg’s framing: “failed to impress.”
I think the market is asking the wrong question. The question isn’t whether NVIDIA can sell chips this quarter. It’s whether $700 billion of annual hyperscaler capex represents the peak of a hardware cycle or the first phase of a permanent economic shift. Jensen Huang used this earnings call to make the most forceful argument yet for the latter, and I think he’s right.
Pre-Recorded vs. Generated

Near the end of the call, Huang said something I keep coming back to:
“The way we used to do software was pre-recorded. Everything was captured a priori. We pre-compile the software, we pre-write the content, we pre-record the videos. Now everything is generative in real time... Just as a computer has a lot more computation capability than a DVD player, artificial intelligence needs a lot more computing capability than the way we used to do software in the past.”
This is the single most important strategic insight from the quarter, not because it’s new, but because it’s now provably true.
For fifty years, software has been pre-recorded. A developer writes code. It compiles. It runs the same way every time. The compute required to execute pre-written instructions is modest and predictable. This is Jensen’s DVD: press play, it runs, done.

Generative software is fundamentally different. When Claude Code takes a coding task, it doesn’t retrieve a stored answer, it reasons. It breaks the problem apart, writes code, tests it, iterates, sometimes spawns sub-agents working in parallel. A single request might generate tens of thousands of tokens over minutes or hours, each requiring real-time computation. The gap between serving a static page and running a multi-step reasoning chain isn’t 2x or 10x. It’s closer to 1,000x.

This changes what compute is. In the pre-recorded world, compute is a fixed cost, write the software once, run it cheaply forever. In the generative world, compute becomes a variable cost tied to the complexity of the task, generated fresh every time. And critically, once those tokens are monetized, once each token represents a unit of economic output, compute stops being a cost center and becomes a revenue engine.
Jensen stated this as a completed axiom, repeated five times across the call: “Compute equals revenues.”
This is why the efficiency bear case misses the point. In a pre-recorded world, efficiency reduces demand, you need fewer servers to run the same code. In a generative world, efficiency lowers the cost per token, which makes new applications economically viable, which explodes total token volume. DeepSeek doesn’t reduce the need for NVIDIA GPUs. DeepSeek makes it cheaper to run reasoning chains, which means more people run more reasoning chains. Jevons Paradox, applied to silicon.
The Agentic Proof Point

The pre-recorded-to-generative thesis is interesting as theory. What makes this quarter different is that the theory now has commercial proof.
Huang was explicit: the agentic AI inflection “literally happened in the last couple of two, three months.” Claude Code, OpenAI Codex, Claude Cowork, these systems have crossed from demos to products. Tokens aren’t speculative anymore. They’re dollarized and profitable.
“Compute directly translates to intelligence and revenue growth. Tokens are profitable.”
He cited Anthropic’s revenue growing 10x in a year while being “severely capacity-constrained”, meaning every additional GPU shipped translates directly into incremental revenue for the model provider. OpenAI’s demand he described as “incredible.” And he noted that NVIDIA’s own engineers use Claude Code, Codex, and Cursor “enormously”, often all three depending on the task.
This matters because it resolves the inference debate. The bear case on NVIDIA always had two chapters: first, training demand would plateau; second, inference would be commoditized to cheaper ASICs. The agentic inflection breaks the second argument. Agentic inference doesn’t look like serving a chatbot response, it looks like training. It requires massive memory bandwidth, sustained GPU utilization across long reasoning chains, and the kind of flexible, programmable architecture that general-purpose GPUs do well and fixed-function ASICs do poorly.
By pushing the market toward agents, systems that think for minutes, not milliseconds, NVIDIA ensures inference remains a premium, high-performance market where its architecture dominates.
The Product Is the Rack

If the generative shift is the why behind compute demand, the infrastructure story is the how behind NVIDIA’s capture of that demand. And the most revealing number in this quarter isn’t revenue or margins, it’s networking.

Networking has gone from 8% to 18% of Data Center revenue in one year, growing 267% YoY in Q4. Full-year networking exceeded $31 billion, 10x what it was in FY21, the first year after the Mellanox acquisition. Jensen claimed on the call that NVIDIA is “probably the largest networking company in the world today.”
Why does this matter? Because it reflects a deliberate shift in what NVIDIA sells. Jensen said it plainly: “We don’t ship nodes of computers. We ship racks of computers.”
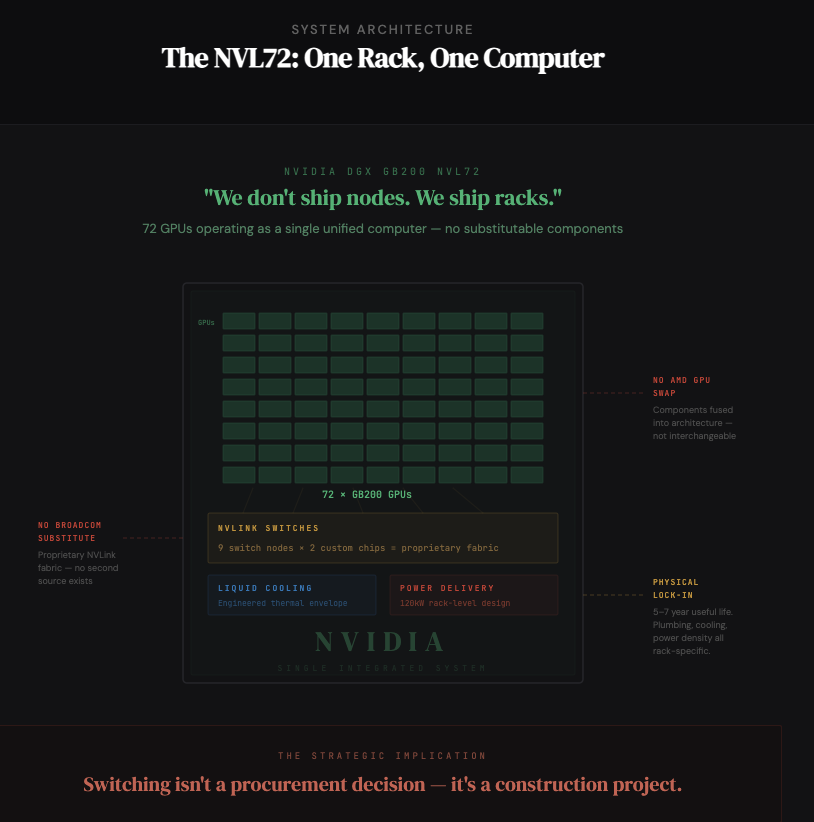
The NVL72 is a single rack-scale computer. Nine NVLink switch nodes, each with two custom chips, connecting 72 GPUs through proprietary fabric with liquid cooling engineered for a specific thermal envelope. You cannot substitute a Broadcom switch or an AMD GPU into this system. The components are fused into an architecture.

This is the moat shifting in real time. A customer can theoretically swap one GPU for another, it’s expensive, but architecturally possible. But once you’ve built your data center around NVL72 racks, plumbed the liquid cooling, provisioned the power density, deployed the NVLink fabric, you are physically locked in for the useful life of that infrastructure. Five to seven years. Switching isn’t a procurement decision; it’s a construction project.
Networking revenue is the tell. It proves customers aren’t buying NVIDIA’s chips. They’re buying NVIDIA’s topology. And topology, unlike chips, has no second source.
Closing the Decode Gap

One more strategic development, smaller in dollar terms than the headline numbers, but potentially significant in competitive implications.
NVIDIA announced a non-exclusive licensing agreement with Groq and, as Jensen put it, “welcomed a team of brilliant engineers to NVIDIA.” His framing:
“As we did with Mellanox, we will extend NVIDIA’s architecture with Groq’s innovations to enable new levels of AI infrastructure, performance, and value.”
Groq built a chip architecture purpose-designed for inference decode, the specific phase where models produce output tokens one at a time. This is the one dimension where specialized silicon has a genuine, physics-based latency advantage over general-purpose GPUs.

The Mellanox comparison is about strategic pattern, not deal structure. In 2019, NVIDIA recognized that as chips got faster, the network would become the bottleneck. They bought the best network company. Now, recognizing that reasoning models require new inference architectures, particularly for the decode phase where agentic systems spend most of their compute, they’re absorbing the innovation leader’s technology and talent.
The intent is clear: bring decode-optimized capabilities inside NVIDIA’s architecture before anyone can use them as a competitive wedge. Jensen promised more details at GTC on March 16. I’d pay attention.
What This Means

Let me connect the threads.
Software is shifting from pre-recorded to generated. This is not a product cycle. It is a change in what software is, and once software becomes generated, the scarce input is compute. If compute is monetized (and agentic AI proves it is), then compute becomes a revenue engine, not a cost center. The $700 billion of hyperscaler capex approaching for 2026 isn’t overbuild. It’s the minimum capacity investment for an economy where software produces fresh output for every query, every user, every task, in real time.
NVIDIA’s Q4 results show a company positioning to capture this permanently. Not just through chips, the GPU is almost beside the point now, but through rack-scale systems where networking generates 18% of revenue and growing, where the unit of sale is the topology, where physical lock-in lasts the better part of a decade. And where NVIDIA is using its extraordinary cash generation ($97 billion in free cash flow last year) to underwrite the very ecosystem that drives demand, $10 billion into Anthropic, billions more into model labs and neo-clouds, strategic supply commitments extending into 2027.
The risk is real: if token economics prove unsustainable, if hyperscaler capex peaks, if Chinese competitors, whom Jensen acknowledged for the first time “have the potential to disrupt the structure of the global AI industry”, find a way in, then the aggressive positioning becomes a liability. NVIDIA is short volatility at historic scale.
But the DVD analogy keeps pulling me back. DVDs didn’t die because people stopped watching movies. They died because streaming was better, more personalized, more responsive, more alive. Pre-recorded software isn’t going to die because people stop using applications. It’s going to be absorbed by generative intelligence that adapts to the user, the context, and the intent, in real time, every time.
The world spent $300-400 billion a year on infrastructure for pre-recorded software. If the new way requires even 100x more compute, let alone 1,000x, then we are in the first inning of a buildout measured in trillions. Jensen sees it. The hyperscalers, based on their capex plans, see it too.
NVIDIA built the system that produces the systems that produce intelligence. This quarter, the system ran at full capacity, the order book extends into 2027, and the market yawned.
It won’t yawn forever.
Disclaimer:
The content does not constitute any kind of investment or financial advice. Kindly reach out to your advisor for any investment-related advice. Please refer to the tab “Legal | Disclaimer” to read the complete disclaimer.